میخواهیم یکسری پیام دیجیتالی را بین دو سیستم تبادل کنیم. در مقصد لازم است پیامها از هم تفکیک شده باشند، تا بتوان آنها را تفسیر کرد و به دادهی مدنظر رسید. جداسازی پیامها چگونه امکان پذیر است؟ در این پست به بررسی الگوریتم COBS که یکی از راههای ممکن برای حل این مشکل است، میپردازیم.
برای جداسازی پیامها راههای مختلفی است. مثلاً میتوانیم هر بار که پیامی ارسال شد، پایهای را صفر و یک کنیم تا گیرنده متوجه این موضوع شود. یا اینکه در انتهای پیام، کارکترهای carriage return (`\r` و `\n`) را ارسال کنیم. در راه اول، چیزی که میتواند باعث نامطلوب بودنش شود، تغییر سختافزار است. ما گاهی به دلیل افزایش هزینه یا حتی عدم امکان این موضوع، به دنبال تغییر سختافزار نیستیم. در راه دوم هم اگر پیامها تنها از کارکترهای متنی (مثلاً شامل حروف انگلیسی، اعداد و چند علامت نگارشی) تشکیل شده باشد، قابل قبول و متداول است. اما اگر پیام ما مثلاً یک عکس بود که بایتهایش هر مقداری از 0x00 تا 0xFF بودند، چطور؟ آیا میتوان در این حالت مثلاً 0x00 یا هر بایت دیگری را به عنوان جدا کننده در نظر گرفت؟
واضحه که پاسخ خیر است. چراکه ممکن است در خود دادهی اصلی ما هم 0x00 ظاهر شود و در این حالت نمیتوان بین پیام اصلی و جداکنندهی پیام تمایز قائل شد.
برای حل این موضوع راهی که گاهی استفاده میشود، اضافه کردن یک بایت یا حتی بیت به جاهایی است که مقدار Delimiter در دادهی اصلی هم رخ داده. فرض کنید قرار میگذاریم هرجا در دادهی اصلی 0x00 دیدیم، یک 0xAA کنارش قرار میدهیم. در نتیجه گیرنده میتواند با احتمال قابل قبولی به درستی تشخیص دهد 0x00 دیده شده جزئی از پیام است یا جدا کنندهی پیام. به این کار Byte Stuffing (یاBit Stuffing در صورت استفاده از الگوی بیتی خاص) گفته میشود.
در اینجا نمیخواهم به بررسی جزئیات الگوریتمهای Byte Stuffing یا Bit Stuffing بپردازم. تنها اشاره کنم که عیب Bit Stuffing در این است که اگر قرار باشد بصورت نرمافزاری بیتها را بررسی کنیم، پردازش نسبتاً زیادی برای این کار لازم است. اگرچه پیادهسازی سختافزاری آن میتواند بهینهتر و مطلوب باشد که اینجا مورد بحث ما نیست.
از معایب Byte Stuffing هم میتوان به این مورد اشاره کرد که اگرچه در بهترین حالت (عدم وقوع بایت Delimiter در پیام)، هیچ بایت اضافهای را به پیام نمیچسبانیم. اما در بدترین حالت (تنها بایت جداساز در پیام باشد)، سایز پیام کدگذاری شده دو برابر میشود. این تغییر سایز بالا، میتواند بعضی جاها دردسرساز باشد.
الگوریتم COBS:
برای حل این موضوع الگوریتم COBS (Consistent Overhead Byte Stuffing) به کمک ما میآید. با کمک این الگوریتم برای ارسال N بایت ما در بهترین حالت، یک بایت و در بدترین حالت (1 + N / 254) بایت به عنوان سربار خواهیم داشت.
هنگامی که قرار باشد 0x00 را به عنوان بایت جداساز در نظر بگیریم، این الگوریتم به جای اضافه کردن بایت(بیت) به پس و پیش 0x00های پیام، آنها را با عددی غیر صفر جایگزین میکند. در نتیجه هرگاه در گیرنده 0x00 را مشاهده میکنیم، مطمئنیم که جداساز پیام است.
اما اینکار چگونه صورت میگیرد که ما در گیرنده میتوانیم مجدد به پیام اصلی دست پیدا کنیم و صفرهای پیام را برگردانیم؟!
در این الگوریتم پیام یا رشته بایت اولیه، به بخشهای کوچکتری تقسیم میگردد. هر بخش با بایتی آغاز میشود که به آن Code میگویند. مقدار Code از0x01 تا 0xFF متغیر است. این مقدار برای ما مشخص میکند که بعد از آن چه تعداد بایت غیر صفر داریم. به جدول زیر دقت کنید.
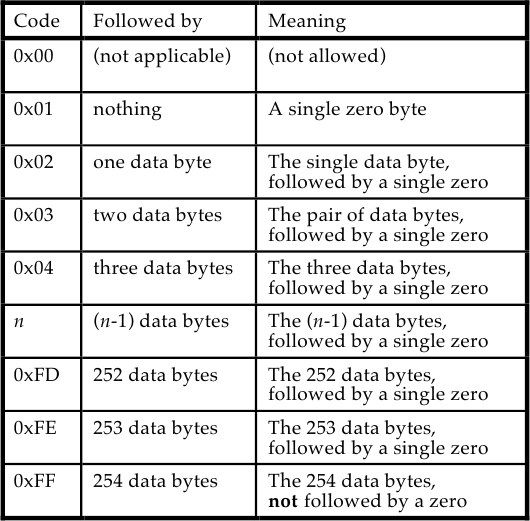
همانطور که مشاهده میکنید، به جز زمانی که مقدار Code عدد 0xFF است، در انتهای هر بخش بایت صفر داریم. پس با این حساب هر بخش دو حالت میتواند داشته باشد. یا اینکه تشکیل شده از Code با مقدار 0xFF و 255 بایت غیر صفر در ادامهاش است. یا اینکه Code یکی از مقادیر 0x01 تا 0xFE را دارد و بعد از داشتن تعدادی بایت غیر صفر (یکی کمتر از عدد Code)، در انتها یک بایت صفر هم دارد.
حالا شاید سوال پیش بیاید که اگر برای جدا کردن آخرین بخش، نه در انتهای دادهها یک بایت صفر داشتیم و نه تعداد بایتهای غیرصفر آخر 254 تا بود، تکلیف چه میشود؟ برای جلوگیری از این مشکل به جز یک استثنا، همیشه یک صفر به انتهای دادهها اضافه میکنند. در این صورت تنها لازم است در مقصد بعد از decoding این صفر اضافی را دور بیندازیم. استثنا هم حالتی است که بخش آخر 254 بایت غیرصفر باشد. این استثنا را برای اندکی بهینهسازی تعریف کردند. چراکه در این حالت یک بایت کمتر ارسال میشود، بدون اینکه برای decoding مشکلی پیش بیاید.
بعد از بخشبندی دادهها به صورتی که گفته شد، کافی است که صفر انتهایی بخشها را در نظر نگیریم و به همان ترتیب بخشها را کنار هم قرار دهیم. از آنجا که صفر انتهای بخشها در دادهی کدگذاری شده ظاهر نمیشوند، به آنها صفر ضمنی هم میگویند.
اگر توجه کرده باشید، در تعریف بالا کد 0xFF یک حالت ویژه است که در انتها صفر ضمنی ندارد. دلیل این استثنا این بوده که بتوانیم تعداد بایتهای غیرصفر بیش از 254 تا را هم بخشبندی کنیم.
مثلاً فرض کنید قرار است 255 بایت داده با مقدار 0xCC فرستاده شود. ابتدا یک بایت صفر به انتها اضافه میکنیم. حالا این رشته را به دو بخش کوچکتر میتوان تقسیم کرد. بخش اول، که با کد 0xFF شروع و با 254 بایت غیر صفر 0xCC خاتمه مییابد. بخش دوم، که با کد 0x02 شروع و با یک بایت غیرصفر 0xCC ادامه مییابد. در انتها هم هم یک صفر ضمنی دارد.
بعد از بخشبندی دادهها به صورت بالا، میتوان رشته بایت کد شده را (بدون صفرهای ضمنیشان) ارسال کرد و در انتها هم با فرستادن یک بایت صفر به عنوان جداکننده، پایان پیام را برای گیرنده مشخص کرد.
برخلاف الگوریتمهای دیگر Byte Stuffing که هر چه رخ دادن بایت جداساز در پیام کمتر بود، سربار پیام هم کمتر میشد، در COBS ما هنگامی کمترین سربار را داریم که عدد صفر بیشتر ظاهر شود. یا به عبارتی تعداد 254 (یا بیشتر) بایت غیرصفر پشت سر هم نداشته باشیم.
در زیر چند مثال دیگر از پیامهای کد شده با COBS مشاهده میکنید، توجه کنید که پیام کد شده حاوی 0x00 جدا کننده نیست. درنتیجه بعد از ارسال هر پیام کد شدهای، یک بایت صفر جدا کننده باید ارسال شود:
پیام اصلی:
0x11 0x22 0x33
پیام کد شده:
0x4 0x11 0x22 0x33
پیام اصلی:
0x00 0x11 0x22 0x00 0x33
پیام کد شده:
0x01 0x03 0x11 0x22 0x02 0x33
پیام اصلی (255 بایت غیرصفر):
0xCC 0xCC 0xCC … 0xCC
پیام کد شده(254 بایت غیرصفر اول با کد 0xFF در بخش اول، یک بایت غیرصفر با کد 0x02، در بخش دوم قرار میگیرد):
0xFF 0xCC 0xCC … 0xCC 0xCC 0x02 0xCC
اگر میخواهید مثالهای بیشتری مشاهده کنید یا اینکه در پروژهی پایتون خود از این پروتکل استفاده کنید، پیشنهاد میکنم به این صفحه مراجعه کنید.
برای پیادهسازی این الگوریتم در زبان C هم میتوانید به اینجا نگاهی بیندازید.
تصویر بالا هم از مقالهی اصلی این الگوریتم با عنوان “Consistent Overhead Byte Stuffing“، آورده شده. برای توضیح بیشتر و کاملتر میتوانید به این مقاله مراجعه کنید.